


Why I'm excited about DSPy
What the future of programming with language models looks like


UPDATE November 2024
After many more months of using DSPY we ultimately ended up stopping using it outside of a few specific use cases
TLDR of why;
Base models got very good and very cheap
Structured outputs and consistency became guaranteed with JSON modes
Maintenance and development of the framework was far too slow
With a space changing so fast, we ultimately found it more flexible to write things in house and stay flexible to any changes in the foundational model apis vs relying on third parties
Library & package design wasn’t great although we liked the original concept, and as team we don’t write much Python
I think there was a lot of right ideas in DSPy, and ultimately its structurally similar to what the models are now doing at inference time, my current sense is scaling inference time is more effective for solving hard problems relative to pre-optimizing prompts prior to inference
Leaving this post up to anyone who is intrigued in reading, and I will leave a further update if we come back to using it again in the future.
A butterfly flaps it’s wings in Brazil, sending a small gust of wind into the atmosphere.
This sets off a chain of atmospheric events. Over time, these changes, interacting with countless other variables, cause a tornado in Texas.
This is the butterfly effect: tiny changes can lead to significant, unpredictable consequences.
Over the last few months (while at Entrepreneur First with Pav) we’ve spent a lot of time working with language models and talking to people working with language models.
Our first product was a solution to help people manage their prompt chains. It was the result of our personal frustration managing prompts in complex pipelines, testing them and trying to control different versions. It’s a problem we hear echo’d all the time when talking to customers.
During these discussion we noticed two broad categories of products which have achieved outsized success in the Generative AI space in relatively short period:
Consumer/Prosumer “GPT wrappers”
Applications which make simple calls to language models (usually to OpenAI) to achieve some goal for a user (eg Chat with PDF)
Infrastructure companies who support these use cases, and attempt to support more complex ones (eg Hosting models with APIs, observability, testing, versioning, fine-tuning-as-a-service)
The third, less successful category (in terms of traction) is people trying to build towards more complex use cases. We spoke to lots of these people, and they constantly told us about the difficulties of building complex pipelines.
Interestingly there’s a large void between the number of companies in the successful and unsuccessful categories - why aren’t more “complex” use cases thriving? Aside from simple use cases being easier and quicker to market, my current thinking is that the current tooling, and the journey of using it, constrains you to a broken paradigm.
The journey of building products with language models goes something like this:
It’s really easy to get started - ChatGPT is basically all you need to get a proof of concept
Then you start trying to do more complex things, such as retrieving your own data and augmenting the prompt with it before the generation (aka RAG).
You realise these things are a bit harder and turn to packages like Langchain which do a great job of making this really easy
The tradeoff here with a ‘batteries included’ framework is an abstraction layer that hides details, while still having hard coded prompt strings
You get a proof of concept (kind of) working
The proof of concept isn’t working for some use case or has some issue that needs a change
You spend time digging into the underlying abstraction only to realise it needs significant changes to fit this use case
You rip apart the example, taking smaller primitives from popular packages and write your own
You realise with more moving components and an extensive amount of hardcoded prompts, you need version control, testing and other services to support the inference calls to language models.
You finally get an example working and now try to change your pipeline (or OpenAI decides to re-lobotomise the model, or you switch model because costs/quality etc…. lots of reasons)
Everything goes kaboom - the butterfly effect
The problem starts when developers move from creating simple products, often with a single fixed prompt, to attempting to construct complicated pipelines that involve several requests, yet still rely on fixed prompts.
If this describes you, don't worry!
From the beginning of your journey, you're trained to use fixed prompts. You use them to interact with ChatGPT, in common libraries, and now you're advised to manage and test these prompts using new B2B SaaS products (like the one we've developed at Outerop)
The problem is actually quite simple to articulate if you take an overly simplistic example and completely ignore every other variable you’d care about like cost, latency etc.
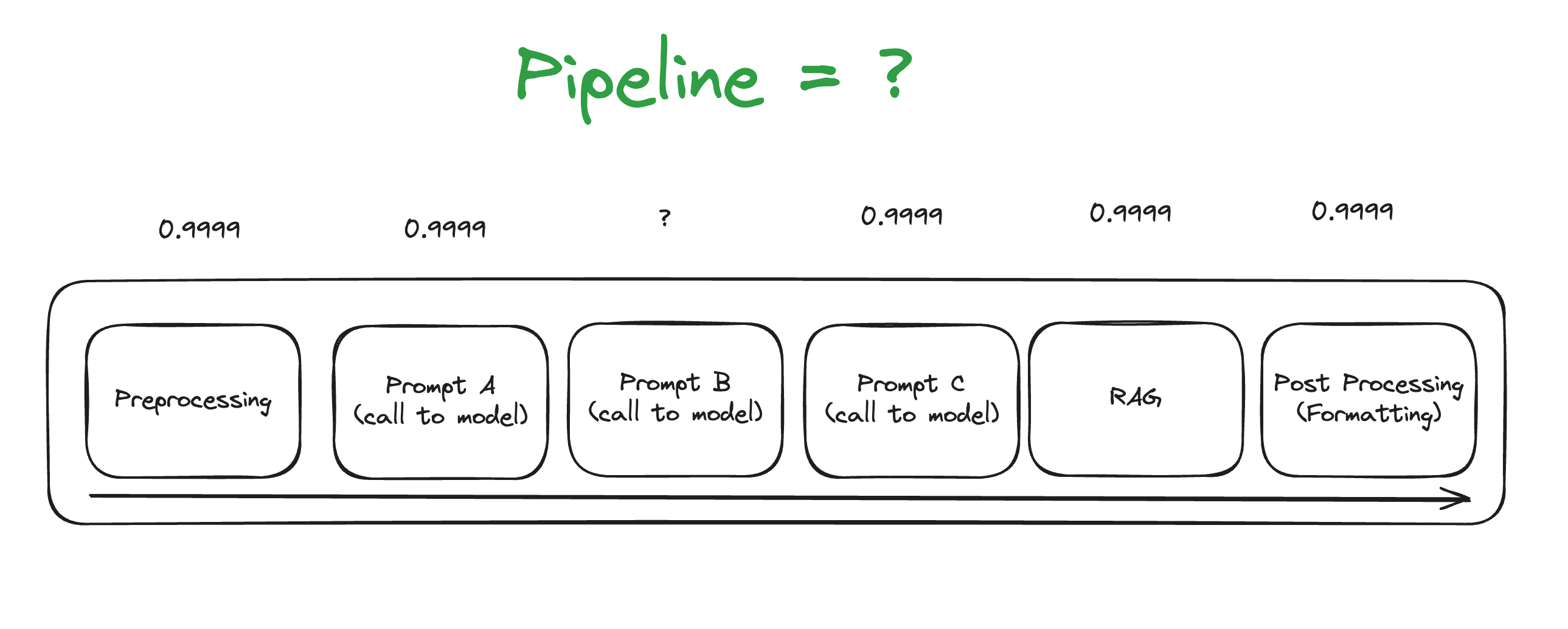
Lets take a hypothetical pipeline of prompts that has 6 steps. Each step passes outputs to be used in the next, and is fully dependent on the previous outputs being correct. We also include a step that retrieves data and augments the next generation text with it (RAG) for fun.
We put a hypothetical accuracy number above of how often it succeeds (quality):

With each prompt having an accuracy of 90%, the pipelines accuracy?

Maybe you upgrade to using a better model for all the calls, you plug in GPT-4 and go through the prompts. They basically work every time! Except for prompt B.
Prompt B violates OpenAI’s content policy in some way. So you plug in Mistral, initial results?

Hmm not great, what if we tweak prompt A?

Iterate until you get it right, and then you need to change something again - kaboom
This leads to a very fragile system that is increasingly difficult to work with as it grows in complexity.
THIS is why I’m excited about DSPy
Last week, after trying and building solutions in this problem space for months, I stumbled upon DSPy. They describe this exact issue when talking about their solution:
“Every time you change one piece, you likely break (or weaken) multiple other components” - https://github.com/stanfordnlp/dspy
This intrigued me enough to try it, and roughly a week (and a lot of code) later I’m pretty much sold on this being part of the solution.
DSPy is a framework for algorithmically optimizing LM prompts and weights, which shines when language models are used one or more times within a pipeline.
The prompts and weights here is important. DSPy can be used to to optimise the prompts without fine tuning the actual model (weights). It also makes it really easy to also do fine tuning on models (weights), if you need it.
Instead of focusing on hand crafted prompts that target specific applications, DSPy has general purpose modules that learn to prompt (or finetune) a language model.
This solves the fragility problem by allowing you to simply recompile the pipeline when you make changes.
And results so far are worth paying attention to:

I think the future of programming with language models looks a lot more like DSPy, with less emphasis on prompting and more on programming, as increasingly complex use cases are solved and simpler use cases are commoditised.
These increasingly complex use cases can only be solved if we can spend more time programming, and not fixing an increasingly fragile pipeline.
Personally I’ve always had a strange feeling when "“prompting” and “programming” while building. They feel like two distinct tasks that don’t really gel. I’ve had a lot of joy from DSPy enabling me to spend more time with my "programming” hat on and letting DSPy worry about wearing the “prompting” hat.
I think this approach is an order of magnitude improvement for developer experience, and that may address the GenAI Fermi paradox—the gap between the number of successful simple use applications and complex ones. This gap might exist because as the complexity of the pipeline increases, changes take longer to fix.
There’s a chaos like element to these seemingly small changes, like a butterfly flapping its wings in Brazil.
Caveats:
This is my first ever Substack post, so if it sucks feel free to send me pointers
If you asked me a few weeks ago my view would probably have been reversed, I would’ve thought the future has less emphasis on programming and a more on prompting.
I’m not an ML engineer (although I have been lucky enough to work with some great ones)
If you’re interested in this problem the (early) DSPy documentation can be found here
I have no association with DSPy or the team - however I will extend the offer of a beer/coffee to all contributors when were in the US in March as it rocks
If you want to check out what we’re working on or talk to myself and Pav you can contact us here
I post hot takes on Twitter/X here
Amazing explanation of why complex applications fail, particularly with the 0.9 accuracy on all steps leading to 0.57 accuracy overall. Pretty much a coin flip that your pipeline will fail. Next step would be an ELI5 visual explanation of DSPy :)
Amazing